We introduce ImageDream, a novel suite of Image-Prompt Multi-view diffusion models devised for the nuanced task of 3D object generation. Distinct from text-only conditioned frameworks, ImageDream harnesses the potent capabilities of image feature inputs, thereby facilitating an additional layer of image prompt/guidance to adeptly steer the 3D object generation process and consider an absolute cononical coordination system rather than relative. This enhancement significantly augments the visual discernibility of the generated 3D models prior to their full generation. In a departure from other State-of-the-Art (SoTA) image-conditioned endeavors, ImageDream excels in delivering 3D models of superior quality, nearing the finesse observed in text-conditioned exemplars like MVDream. Our models are meticulously crafted, taking into account varying degrees of control granularity derived from the provided image: wherein, the global control predominantly influences the object layout, whereas the local control adeptly refines the image appearance. The prowess of ImageDream is empirically showcased through a comprehensive evaluation predicated on a common prompt list as delineated in MVDream.
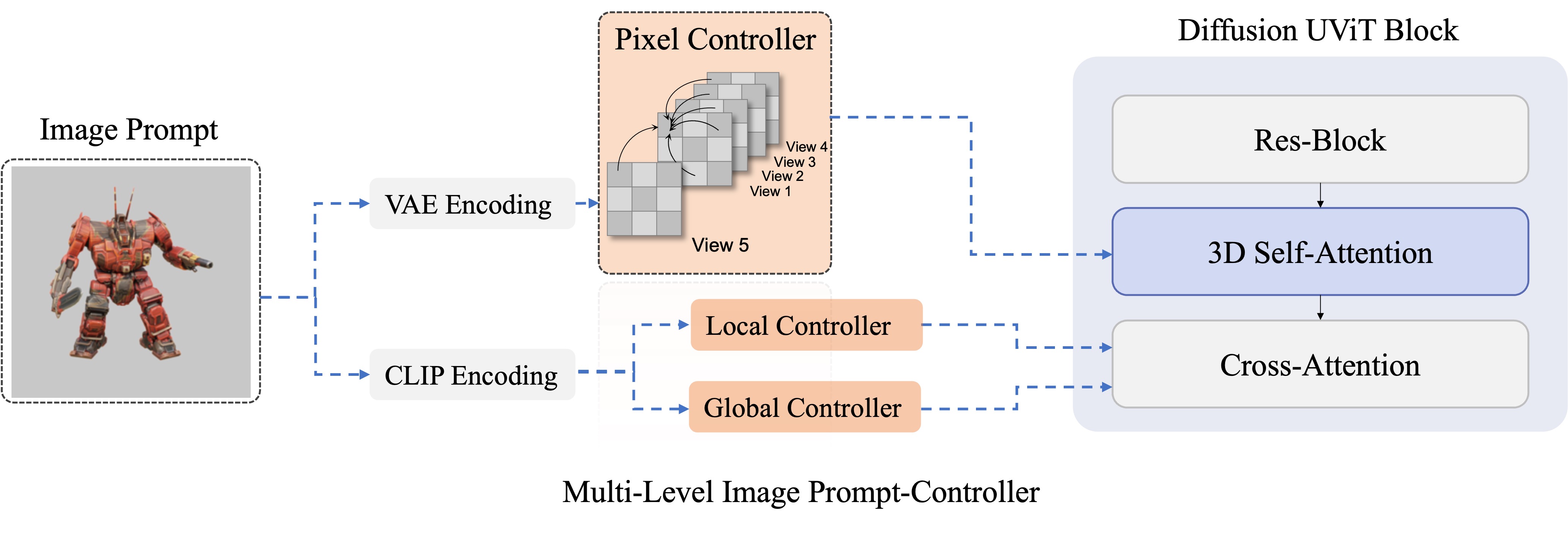
Below, we elucidate the integration of the Multi-Level Image-Prompt Controller from ImageDream within the diffusion model architecture of UNet, supplementing the original text embedding and four-view camera embedding as deployed in MVDream.
Our image-prompt multi-view diffusion model can be easily conjucted with score distillation, where only single stage SDS Fusion is performed.
ImageDream generates objects and scenes in a multi-view consistent way.

A bulldog wearing a black pirate hat


a ghost eating a hamburger


an astronaut riding a horse

We adopt 39 prompts from MVDream and generated images using SDXL to compare with other image-to-3D methods. A fixed default configuration is used for all prompts without hyper-paramter tuning with threestudio. ImageDream-G means the results only using CLIP features. ImageDream-P means results with both features.
Input Image
Zero123-XL
Magic123
SyncDreamer
ImageDream-G
ImageDream-P
an astronaut riding a horse

Samurai koala bear

A bald eagle carved out of wood

girl riding wolf, cute, cartoon, blender
a ghost eating a hamburger
@article{wang2023imagedream,
author = {Wang, Peng and Shi, Yichun},
title = {ImageDream: Image-Prompt Multi-view Diffusion for 3D Generation},
journal = {arXiv preprint arXiv:2312.02201},
year = {2023},
}